開頭先瞭解一下什麼是串流,來自維基百科

串流媒體(streaming media)是指將一連串的媒體資料壓縮後,經過網路分段傳送資料,在網路上即時傳輸影音以供觀賞的一種技術與過程,此技術使得資料封包得以像流水一樣傳送;如果不使用此技術,就必須在使用前下載整個媒體檔案。
同常有一個情況是這樣的,如果我要讓用戶下載自己的交易記錄,假設有五萬筆好了
- 用戶點擊下載後,開始準備資料、輸出資料,如果資料量稍大,網頁這時候會卡住,因為在等 server 回應
- 用戶點擊下載後,隨後跳出通知用戶幾分鐘後會收到 Email, 由異步執行的 worker 去處理(例如 Sidekiq)
不管是一或二我個人認為對使用者都不是很好的體驗。
第一種作法會讓覺得網站是不是當機了,如果超過一分鐘, server 又將我斷開連接,直接給我一個 504,我會很崩潰的。 第二種作法雖然將工作拆至背景作業,身為使用者的我也無法知道當前的進度,而且有可能會掉信?
當然第二種作法如果還遇到商業邏輯是用手機註冊的就行不大通了,難不成要輸出報表前讓用戶先去進行郵箱驗證?
在 Rails 中其實可以實現串流下載,這樣當資料準備到多少,用戶就會下載到多少,當用戶中斷下載,執行的部分也會直接斷掉。
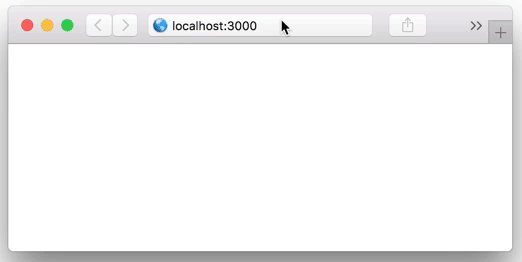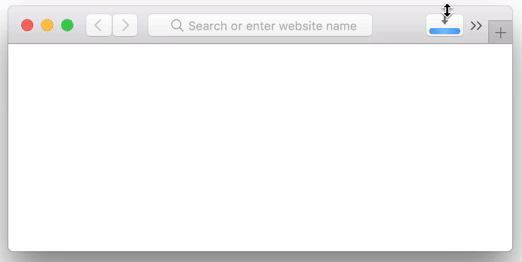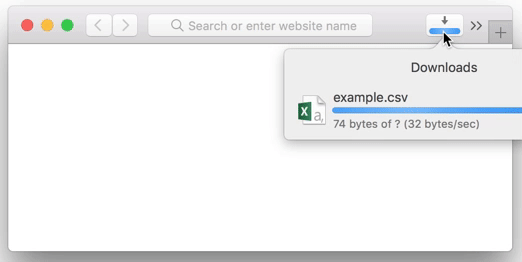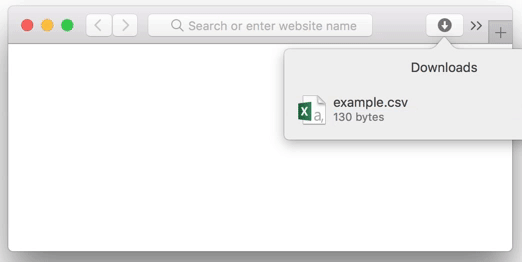
那麼,如何實做呢?
class OrdersController
def index
respond_to do |format|
format.csv render_csv
end
end
private
def render_csv
set_file_headers
set_streaming_headers
response.status = 200
self.response_body = orders_csv_enumerator(orders)
end
def set_file_headers
file_name = "orders.csv"
# 告訴 Browser 這是 CSV file
headers["Content-Type"] = "text/csv"
# 使用指定的文件名稱下載文件
headers["Content-disposition"] = "attachment; filename=\"#{file_name}\""
end
def set_streaming_headers
# 通過代理服務器時不要緩衝
headers["X-Accel-Buffering"] = "no"
# 從這個 endpoint 建立時不要 cache 任何東西
headers["Cache-Control"] ||= "no-cache"
# 讓 Rack 知道要做串流
headers.delete("Content-Length")
end
def orders_csv_enumerator(orders)
ExportService::Order.new(orders).build_csv_enumerator
end
end
Order csv enumerator 我是另外用 service 做,這樣比較不會混亂。
class ExportService::Order
def initialize(orders)
@orders = orders
end
def build_csv_enumerator
csv_enumerator =
Enumerator.new do |yielder|
yielder << CSV.generate_line(order_headers).to_s
@orders.find_each do |order|
yielder << CSV.generate_line(order_row(order)).to_s
end
end
csv_enumerator
end
end
整個數據過程如下:
我們呼叫使用 lazy enumerator(惰性枚舉器) 的 build_csv_enumerator 方法
由於 response body 由 rails 處理,他不斷要求 enumerator 輸出下一筆資料,為了生成下一筆資料,CSV.generate_line 會請求下一筆數據,直到第一批資料完成(這裡是 find_each, 預設批次處理是 1000 筆資料)之後下發送給瀏覽器,過程中無需一次性生成文件,而是堆疊起來,就是我們實現的串流式下載了。